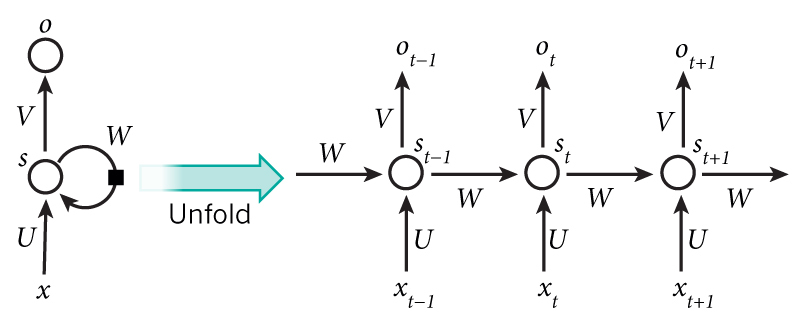
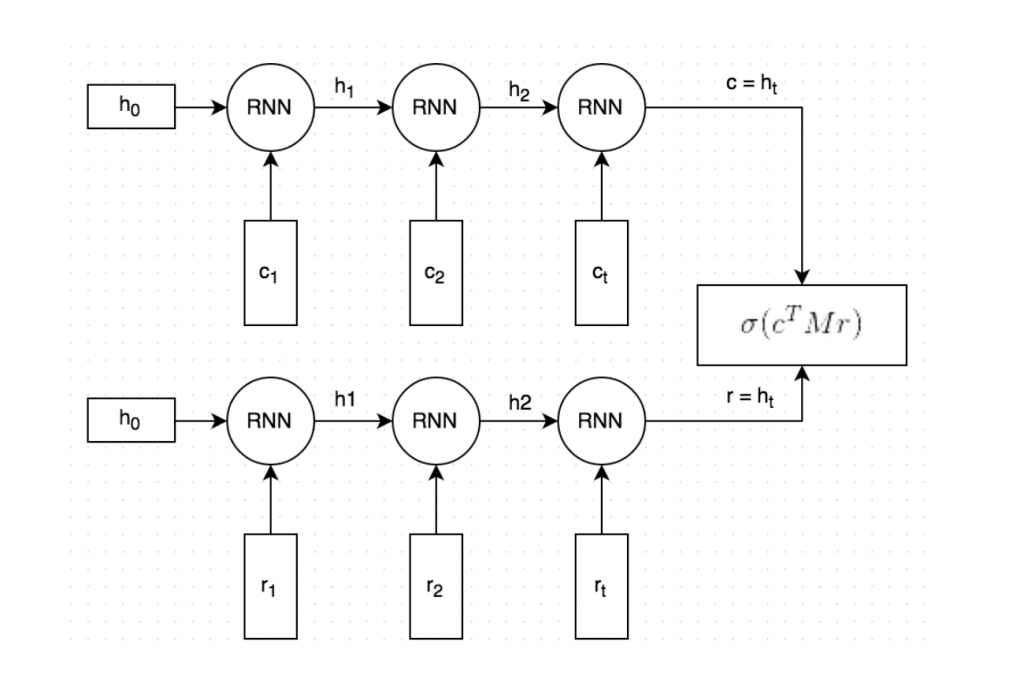
NLP 기술이란?
사람이 말하고 쓰는 것들을 사람의 개입 없이 기계가 이해할 수 있는 형태로 만드는 것 또는 그러한 형태를 사람이 이해할 수 있게 만드는 것을 자연어 처리 기술이라고 합니다. 컴퓨터가 이해할 수 있는 형태로 표현하고자 한다는 점에서 인공지능과 밀접한 관련이 있고 딥러닝과 함께 각광받는 기술 중 하나입니다.
Opinion Mining
SNS, 포털 사이트, 쇼핑몰 등으로부터 여러 의견을 담은 글을 대량으로 수집하여, 몇 가지 주제에 대한 의견을 분석하는 것을 Opinion Mining 이라고 합니다. 이 기술을 통해 특정 제품에 대한 고객들의 의견을 종합하여 다음 제품에서 그 의견들을 적용할 수도 있습니다. 즉, 텍스트를 분석해 필요한 의미 정보를 추출하려는 시도라고 할 수 있을 것입니다.
Curation
구글 광고나 쇼핑몰 사이트에서 자신이 관심있어 하고 필요한 상품들을 보여주는 것은 이제는 흔한 일입니다. 이렇게 사용자의 패턴을 분석하여 사용자의 선호도나 의도에 맞게 콘텐츠를 제공하는 것을 Curation이라고 합니다.
Question Answering
질문을 분석하여 그 의도를 알아내고 그에 적합한 대답을 도출해내는 기술을 Question Answering 이라고 합니다. 이 기술의 대표적인 예시로는 IBM의 Watson이 2011년에 퀴즈쇼에서 우승한 것이 있을 것입니다. 다양한 기술들이 융합되었지만 질문을 분석하고 정답을 탐색하는 것은 반드시 자연어 처리 기술이 필요합니다.
Narrative Technology
Narrative Technology는 특정한 주제에 대해 사람들이 쉽게 이해하도록 자연스럽게 자동으로 글을 쓰는 기술을 말합니다. 아마 인공지능이 기사를 작성한다는 이야기는 들어보셨을 것입니다. 최근에는 주어진 어떤 사건에서 주어진 관점으로 글을 쓰는 기술도 연구되고 있다고 합니다. 이 기술은 쉽게 이해하기 어려운 표나 차트를 쉽게 말로 풀어쓰는 등으로도 응용될 수 있습니다.
Personal Assistant
위와 같은 기술들을 자연어 인터페이스를 제공하여 디바이스(스마트폰 등)나 메신저에서 서비스를 제공하는 것을 Personal Assistant라고 합니다. 대화를 통해 서비스의 질을 높이려는 Siri를 대표적인 예로 들을 수 있을 것입니다.
마치며
챗봇을 만들겠다며 여러 자료들을 조사하고 공부를 하였지만, 생각해보니 자연어 처리가 정확하게 무엇이고 어떤 것들이 있는지는 잘 몰랐던 것 같습니다. 우선 서두르지 않고, NLP, NLU 기술들을 공부하며 정리해나가고 싶습니다.
참고
http://blog.ncsoft.com/?p=4837
https://ko.wikipedia.org/wiki/%EC%9E%90%EC%97%B0_%EC%96%B8%EC%96%B4_%EC%B2%98%EB%A6%AC
'인공지능 > NLP' 카테고리의 다른 글
| DEEP LEARNING FOR CHATBOTS - Part 2 (0) | 2017.04.10 |
|---|---|
| DEEP LEARNING FOR CHATBOTS - Part 1 (0) | 2017.03.28 |
| 텍스트를 기계가 이해하는 방법 (0) | 2017.03.27 |

NCookie