
참고
http://www.wildml.com/2016/07/deep-learning-for-chatbots-2-retrieval-based-model-tensorflow/ - 원문http://mlduck.tistory.com/7 - 번역
DEEP LEARNING FOR CHATBOTS - Part 2
- 이번에는 검색기반 봇을 구현할 것임
- 생성 모델이 좀 더 유연한 반응을 끌어낼 수 있지만 실용화 단계는 아님
- 수 많은 훈련 데이터가 필요하고 최적화가 어렵기 때문
- 현존하는 대부분의 챗봇은 검색기반 또는 검색기반과 생성 모델을 결합한 것임
- 그렇다면 Schedule Manager 에서는 일정 관리 대화만 검색기반으로 하고 나머지 도메인은 생성 모델로 하는건 어떨까?
data set
- buntu Dialog Corpus (UDC) 는 이용가능한 가장 큰 공개 대화 데이터셋 중 하나
- 훈련 데이터는 1,000,000 개의 예제와 50% 긍정 (label 1), 50% 부정 (label 0)으로 이루어져있음
- 각 예제는 문맥과, 그 시점까지의 대화, 발언utterance, 문맥에 대한 응답으로 구성
- 긍정은 실제 문맥에 대한 옳은 응답인 것이고 부정은 정답 외에 랜덤으로 뽑음
- 모델 평가 방법 : reacll@k
- 모델이 10개의 가능한 응답 중 k개의 좋은 응답을 고르도록 함
- 이 중에서 정답이 있다면 그 예제는 정답 처리됨
- 따라서 k가 커질수록 정답률이 높아짐
- k=10 이면 100% 의 recall 을 얻음
- k=1 이면, 모델은 정답 응답을 고를 단 한번의 기회밖에 없음
- 이 데이터셋에서 9 distractors는 랜덤하게 골라졌지만, 실제 세계에서는 몇 백만개의 가능한 응답이 있을 수 있고, 어느 것이 옳은지 모름
- 이 모든 것을 평가하는 것은 비용이 너무 큼
- 아니면 가능한 응답이 몇 백개 정도 밖에 없다면 모두 평가할 수 있음
- Google Smart Reply 는 클러스터링 기술을 사용하여 처음부터 선택할 수있는 일련의 가능한 응답을 제시함
BASELINES
- 어떤 종류의 성능을 원하는지 이해하기 위해 간단한 baseline 모델(자세한 설명은 주석에)
def evaluate_recall(y, y_test, k=1): # recall@k 알고리즘을 구현한 함수
num_examples = float(len(y))
num_correct = 0
for predictions, label in zip(y, y_test):
if label in predictions[:k]: # k 개의 prediction 중 정답(label)이 있는지 확인
num_correct += 1 // prediction 에서 앞쪽에 있을수록 높은 점수를 얻은 것임
return num_correct/num_examples # 정답률을 반환함
- first one (index 0) is always the correct one because the utterance column comes before the distractor columns in our data.
- 이 부분은 잘 이해가 되지 않음...
# Random Predictor
def predict_random(context, utterances):
return np.random.choice(len(utterances), 10, replace=False)
# 10개를 중복 없이 랜덤으로 추출함
# Evaluate Random predictor
y_random = [predict_random(test_df.Context[x], test_df.iloc[x,1:].values) for x in range(len(test_df))]
y_test = np.zeros(len(y_random))
for n in [1, 2, 5, 10]:
print("Recall @ ({}, 10): {:g}".format(n, evaluate_recall(y_random, y_test, n)))
- original paper에서 언급한 것은 random predictor가 아니라 tf-idf 임무
- term frequency – inverse document frequency : 문서에서의 단어가 전체 문서집합에서 상대적으로 얼마나 중요한지를 측정
- 직관적으로, 문맥과 응답이 비슷한 단어를 가지고 있다면, 그 둘은 올바른 쌍일 가능성이 큼
- 적어도 random predictor 보다는 가능성이 높음
- 그렇지만 여전히 만족스러운 성능은 나오지 않음
- tf-idf는 중요한 신호가 될 수 있는 단어의 순서를 무시함
- 따라서 이를 보완할 neural network를 함께 사용
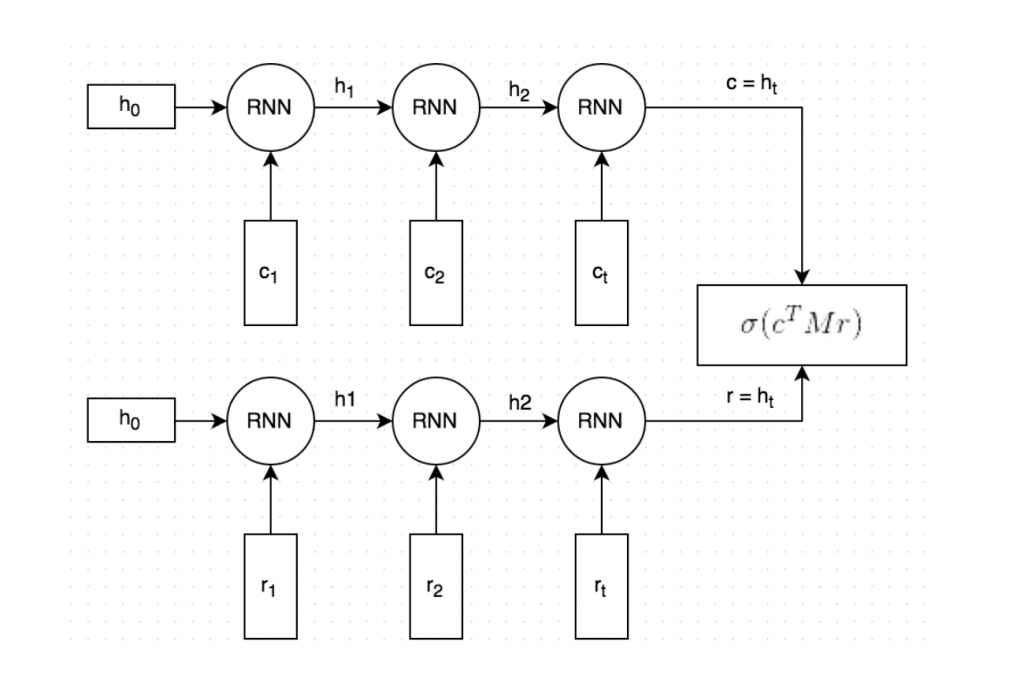
DUAL ENCODER LSTM
- Dual Encoder LSTM network
- 이 타입의 네트워크는 이 문제에 적용할 수 있는 모델 중 하나임
- 물론 가장 좋은 것은 아님
- 기계 번역 분야에서 자주 쓰이는 seq2seq 도 이 문제에 적합함
- 여기서 Dual Encoder 를 사용하는 이유는 이 문제에 대해 성능이 잘 나온다는 논문이 있기 때문(본문의 링크 참조)
'인공지능 > NLP' 카테고리의 다른 글
| 자연어 처리(Natural Language Processing) (1) | 2017.05.17 |
|---|---|
| DEEP LEARNING FOR CHATBOTS - Part 1 (0) | 2017.03.28 |
| 텍스트를 기계가 이해하는 방법 (0) | 2017.03.27 |

NCookie