
아래 내용들은 위 블로그들의 내용을 정리한 것입니다.
- RNN 기반의 언어 모델
- 언어 모델은 두 가지로 응용될 수 있음
- 실제 세상에서 어떤 임의의 문장이 존재할 확률이 어느 정도인지에 대한 스코어를 매기는 것
- 문장이 문법적으로나 의미적으로 어느 정도 올바른지 측정할 수 있도록 해주고, 보통 자동 번역 시스템의 일부로 활용됨
- 새로운 문장의 생성
- 셰익스피어의 소설에 언어 모델을 학습시키면 셰익스피어가 쓴 글과 비슷한 글을 네트워크가 자동으로 생성
- 실제 세상에서 어떤 임의의 문장이 존재할 확률이 어느 정도인지에 대한 스코어를 매기는 것
RNN이란?
- 기존의 신경망 구조에서는 모든 입력(과 출력)이 각각 독립적이라고 가정했지만 대부분의 경우는 이에 적합하지 않음
- 순차적인 정보를 처리
- 동일한 태스크를 한 시퀀스의 모든 요소마다 적용
- 출력 결과는 이전의 계산 결과에 영향
- RNN은 현재까지 계산된 결과에 대한 "메모리" 정보를 갖고 있다고 볼 수도 있음
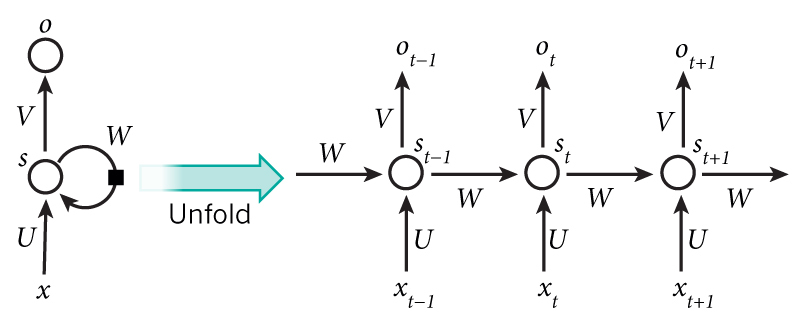
- x_t 는 시간 스텝(time step) t에서의 입력값임 - s_t 는 시간 스텝 t에서의 hidden state. 네트워크의 '메모리' 부분 -

- 이 때 f는 보통 tanh 나 ReLU 가 사용됨 - 첫 hidden state를 계산하기 위한 s_t-1 은 0으로 설정됨 *** - s_t는 과거의 시간 스텝들에서 일어난 일들에 대한 정보를 전부 담고 있고, 출력값 o_t는 오로지 현재 시간 스텝 t의 메모리에만 의존 - 실제 구현에서는 너무 먼 과거에 일어난 일들은 잘 기억하지 못함 *** - 모든 시간 스텝에 대해 파라미터 값을 전부 공유하고 있음 (위 그림의 U, V, W) - 이는 RNN이 각 스텝마다 입력값만 다를 뿐 거의 똑같은 계산을 하고 있다는 것을 보여줌 - 이는 학습해야 하는 파라미터 수를 많이 줄여줌 *** - 위 다이어그램에서는 매 시간 스텝마다 출력값을 내지만, 문제에 따라 달라질 수 있음 - 예를 들어, 문장에서 긍정/부정적인 감정을 추측하고 싶다면 굳이 모든 단어 위치에 대해 추측값을 내지 않고 최종 추측값 하나만 내서 판단하는 것이 더 유용할 수도 있음 - 마찬가지로, 입력값 역시 매 시간 스텝마다 꼭 다 필요한 것은 아님 RNN에서의 핵심은 시퀀스 정보에 대해 어떠한 정보를 추출해 주는 hidden state이기 때문
RNN으로 할 수 있는 일
- 가장 많이 사용되는 RNN의 종류는 LSTM
- hidden state를 계산하는 방법이 조금 다를 뿐 나머지는 거의 같음
- 언어 모델링과 텍스트 생성
- 주어진 문장에서 이전 단어들을 보고 다음 단어가 나올 확률을 계산해주는 모델
- 어떤 문장이 실제로 존재할 확률이 얼마나 되는지 계산
- 부수적인 효과로 생성(generative) 모델을 얻을 수 있음
- 문장의 다음 단어가 무엇이 되면 좋을지 정하면 새로운 문장을 생성할 수 있음
- 네트워크를 학습할 때에는 시간 스텝 t에서의 출력값이 실제로 다음 입력 단어가 되도록 o_t=x_{t+1}로 정해줌
- 자동 번역 (기계 번역)
- 입력이 단어들의 시퀀스라는 점에서 언어 모델링과 비슷하지만, 출력값이 다른 언어로 되어있는 단어들의 시퀀스임
- 입력값을 전부 다 받아들인 다음에서야 네트워크가 출력값을 내보냄
- 언어마다 어순이 다르기 때문에 대상 언어의 첫 단어를 얻기 위해 전체를 봐야할 수도 있음
- 음성 인식
- 사운드 웨이브의 음향 신호(acoustic signal)를 입력으로 받아들이고, 출력으로는 음소(phonetic segment)들의 시퀀스와 각각의 음소별 확률 분포를 추측할 수 있음
- 이미지 캡션 생성
- CNN과 RNN을 함께 사용하여 임의의 이미지를 텍스트로 설명해주는 시스템을 만들 수 있음
RNN 학습하기
- 학습 과정은 기존의 뉴럴넷과 크게 다르지 않음
- 다만 time step 마다 파라미터를 공유하기 때문에 기존의 backpropagation을 그대로 사용할 수는 없음
- 대신 Backpropagation Through Time (BPTT)라는 알고리즘을 사용함(추후 다룰 예정)
- vanishing/exploding gradient라는 문제 때문에 긴 시퀸스를 다루기 어려움
- LSTM 과 트릭 등을 통해 이러한 문제점 해결
RNN - 확장된 모델들
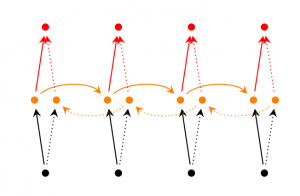
- Bidirectional RNN
- 시간 스텝 t에서의 출력값이 이전 시간 스텝 외에, 이후의 시간 스텝에서 들어오는 입력값에도 영향을 받을 수 있다는 아이디어에 기반
- 출력값은 앞, 뒤 두 RNN의 hidden state에 모두 의존하도록 계산됨
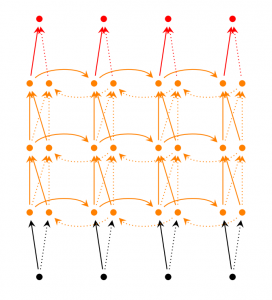
- Deep (Bidirectional) RNN
- 위의 구조에서 layer 의 개수가 늘어남
- 학습할 수 있는 capacity가 늘어나며 그만큼 필요한 학습 데이터 또한 많이 필요함
- LSTM
- 뉴런 대신에 메모리 셀이라고 불리는 구조 사용
- 입력값으로 이전 state h_t-1와 현재 입력값 x_t를 입력으로 받는 블랙박스 형태(???)
- 메모리 셀 내부에서는 이전 메모리 값을 그대로 남길지 지울지 정하고, 현재 state와 메모리 셀의 입력값을 토대로 현재 메모리에 저장할 값을 계산
- 긴 시퀀스를 기억하는데 매우 효과적
'인공지능 > Deeplearning' 카테고리의 다른 글
| weight 초기화 (0) | 2017.03.06 |
|---|

NCookie